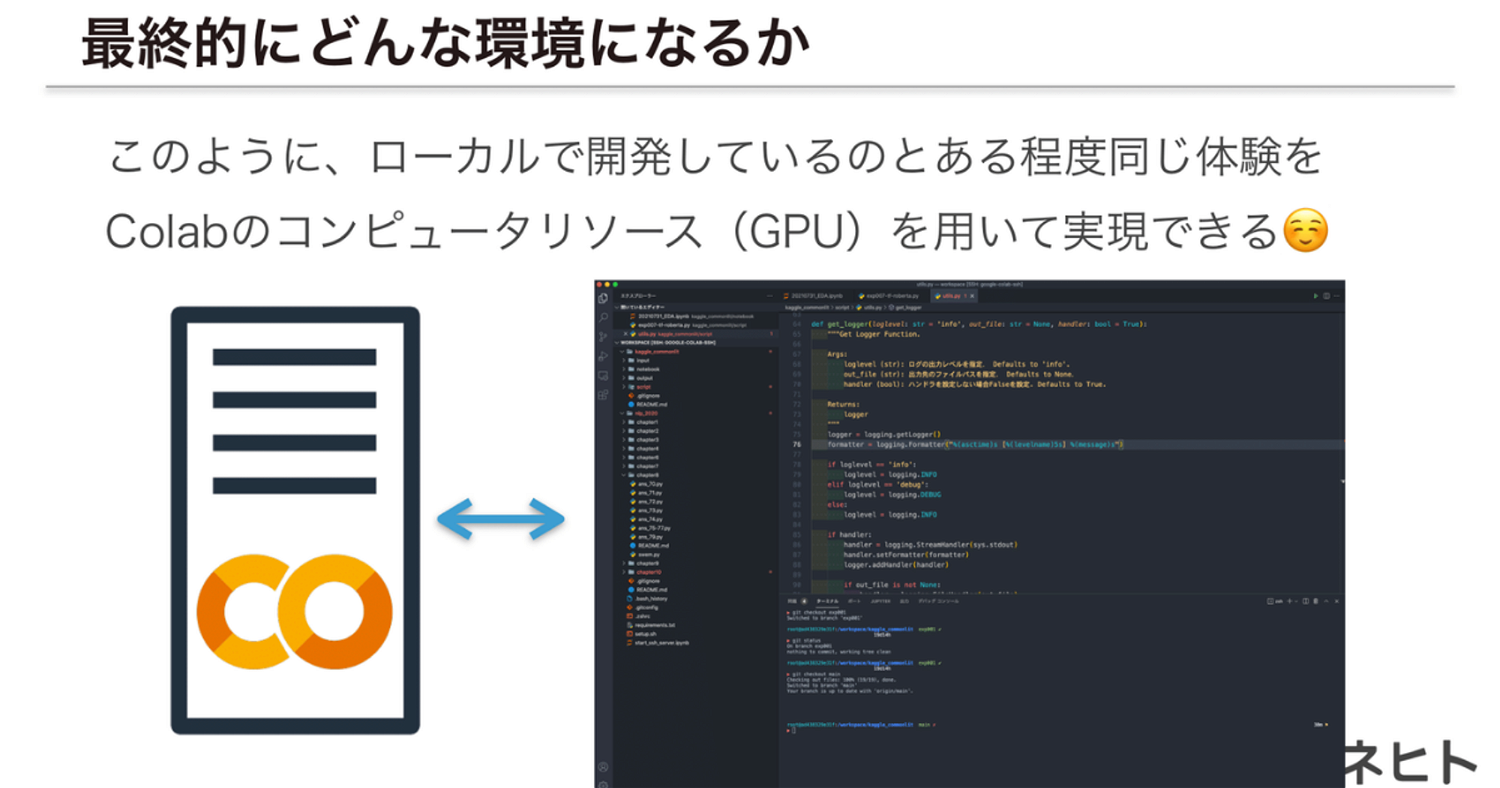
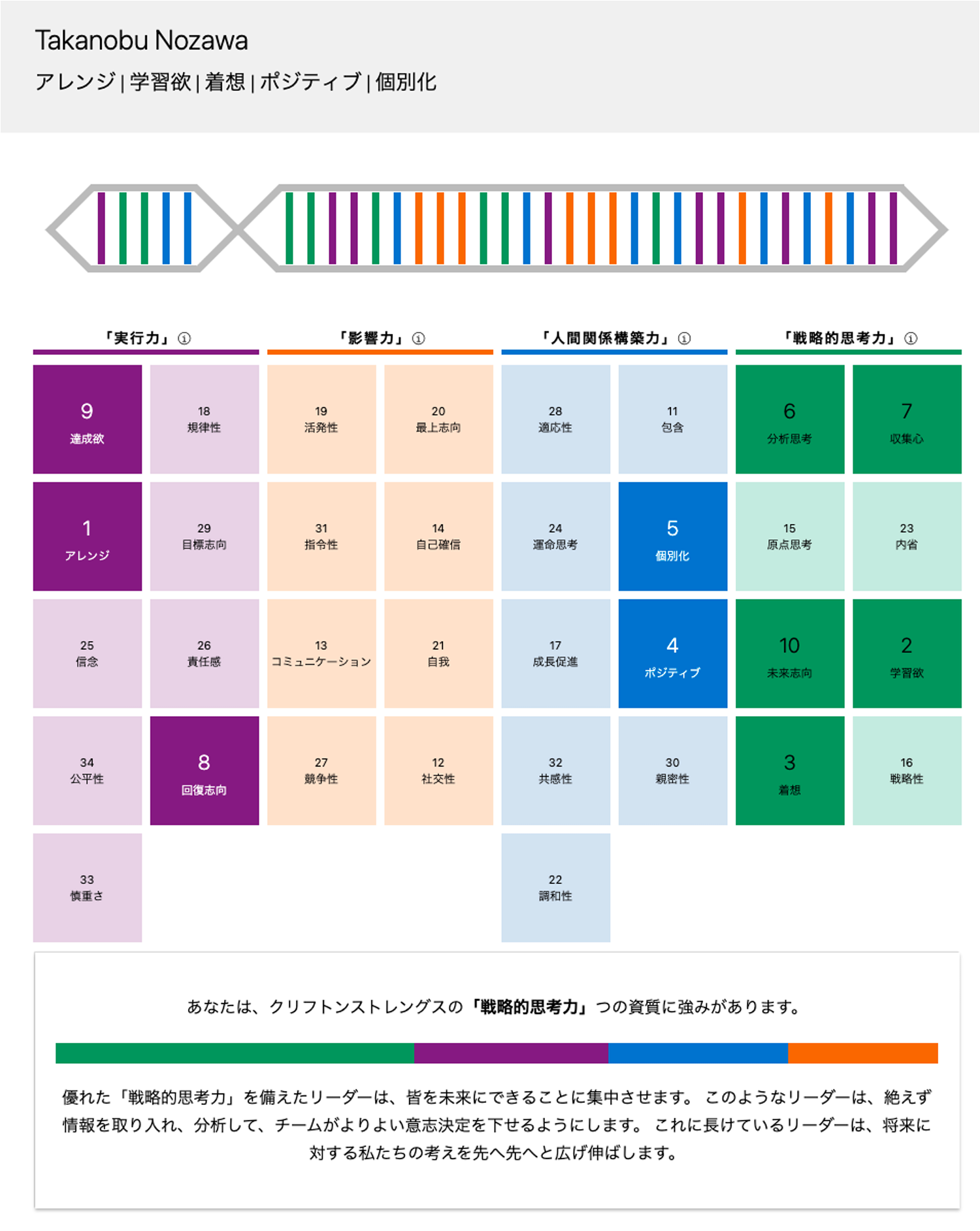
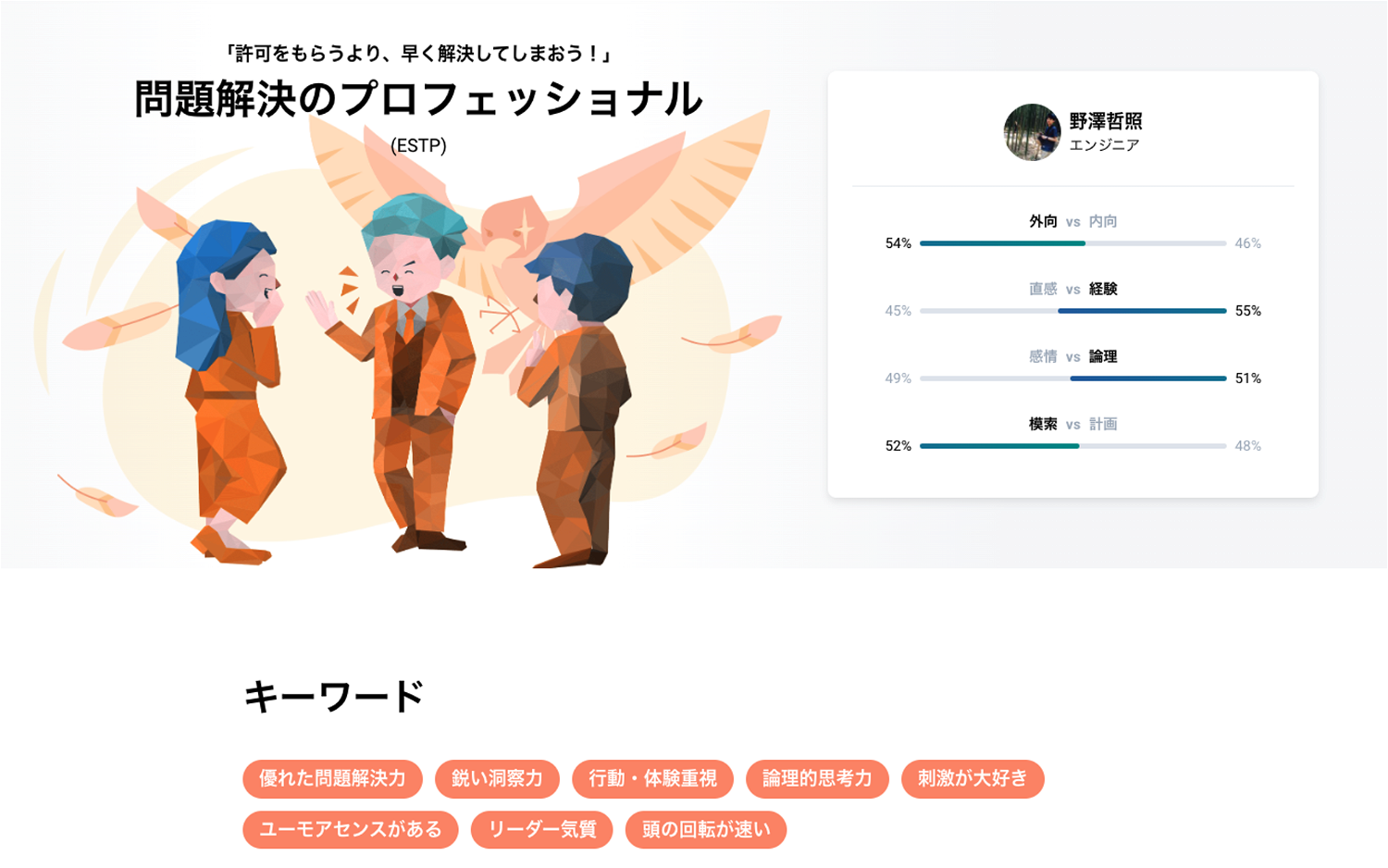
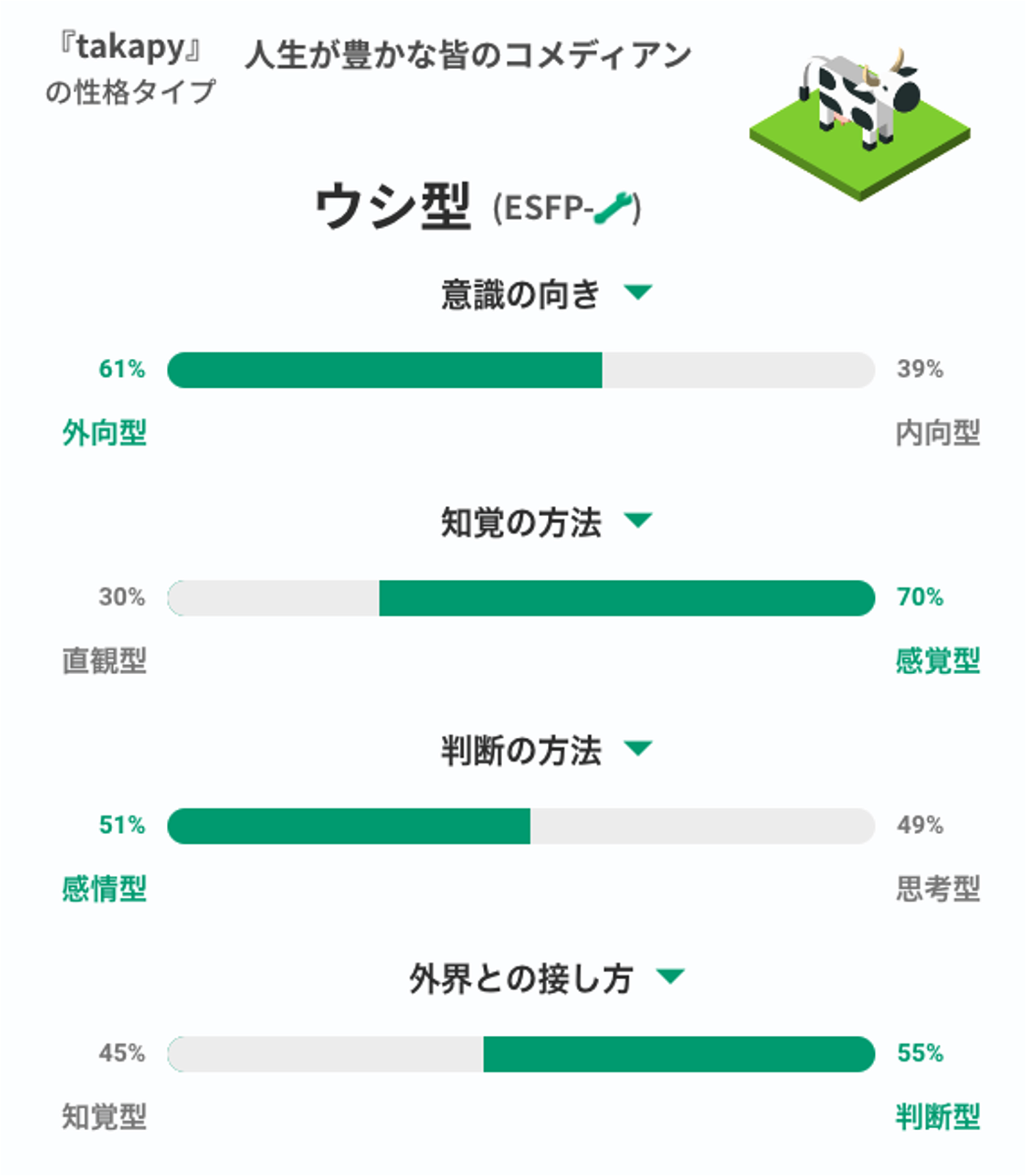
最終更新日:2024年12月
Summary
名前:野澤 哲照(Takanobu Nozawa)
ニックネーム:takapy(たかぱい)
誕生日:1991年2月10日
山梨大学工学部、コンピュータメディア工学科(現:コンピュータ理工学科)を2013年に卒業し、新卒でSIerに就職。製造業向けのERPパッケージの開発・導入に5年ほど従事しました。
その後趣味で勉強し始めた機械学習の面白さにハマり、1人目のMLエンジニアとして2019年にコネヒト株式会社へ入社しました。
入社以降、メインプロダクトであるQAコミュニティアプリ「ママリ」において、コミュニティの検閲システムやレコメンドシステムの導入、検索システムのリプレイスなどを実施しました。また、全社向けデータ基盤を0から構築するなど、データ周辺の業務に従事しております。
2022年からはEngineering Managerとして4名のピープルマネジメント、組織開発などに携わりました。
2024年10月からはアプリのプロダクトマネージャー(PdM)も兼務し、プロダクトの戦略立案やその実行なども行なっています。
アルゴリズムより先ずはユーザー心理を考え「どのような時に、どのような体験をユーザーに与えたいか」という部分から逆算して、機械学習などの技術をどう活かせるか、ということを常に考えながら働いています。
真面目そうに見えるかもしれませんが、オンとオフのギャップがあるとよく言われます。納会の幹事などは積極的にやるタイプです。
各種ご連絡はXのDM、もしくはこちらのお問い合わせフォームからお願いします!